It’s a bit hard to find, but New Rules for Classic Games, by Wayne Schmittberger, is full of intriguing ideas and creative takes on well-known games. It was originally published back in 1992. As the subtitle says “Recycle those old boards for thousands of hours of fun with new rules for Monopoly, Scrabble, Risk, Go, Trivial Pursuit, and more.” In modern terms, these new rules are remixes of classic board games.
It delivers on what it promises, but I was delighted to find it more than just a catalogue of alternative game ideas. The author applies successful game mechanics taken from one game to another, and in doing explores the space of game design possibilities.
Already in Chapter 2 “Fixing a Flaw”, the goal is to create a better game by analysing a balancing problem with older board games and testing different solutions to it. In doing so, the author shows how approaches like the “pie rule”, the “bidding rule”, and playing multiple boards at once can be applied to almost any game of this type.
Chapter 4 “Changing the Number of Players” talks about the challenge of three-player games, which suffer from the “petty diplomacy” problem of 2 players easily being able to team up on a third. The author talks about an approach used by a three-player variant of Japanese chess in which the attacks from 2 players on a third is automatically detected by the game rules, at which point the 2 players must form a team, and the third player is given extra advantages that balances the match.
The discussion of handicapping (Chapter 6) is a mine of great ideas, taken from games like Go and Shogi that have elegant handicapping systems. The author has applied these principles to games as different as Trivial Pursuit and Monopoly, which demonstrates how general they are.
Hidden among the number of game variants of Checkers are some entirely new games like Fields of Action and Epaminodas, which use these cool mechanics of moving lines of checker pieces in order to battle each other. Emergo is another one, in which captured checker pieces are stacked on the bottom of the capturing piece, and the capturing player continues to move her stacks like a single piece. When a stack itself is captured, pieces are taken off the top, so that a player can get their pieces back again.
There are also some fantastic chess variants, such as Extinction Chess, in which you need to keep at least one of each type of piece in play, and Racing Kings, where the goal is to get your king to the other side of the board safely.
The book ends with a description of “postal play”, a practice that I had never heard of. Though I imagine it has since been replaced by the Internet, it was fun to hear how players used to send post cards back and forth to each other, making moves on several games at once in order to be more efficient. Apparently some players appreciated the slowness of process, beause it gave them more time to reflect without the pressure. POstal play posed challenges for simulating randomness (such as a dice rolls). The book proposes elegant solutions to these problems, based on using public, verifiable, but random information such as the daily temperature of London of the closing proce of the stock market. There is also the “diceless dice games”, in which players write down each possible dice roll, and get to use each exactly once during the game.
Finally, the book ends with a bunch of guidelines for “creating your own successful variants”, though I think of them as general game design principles as well. Here are some highlights:
Prefer rule changes that give players more choices
Improve offense, weaken defense
Experiment with changing the goal of the game, or the geometry of the space
Try simulaneous movement instead of sequential movement, or letting players do more than one thing on a turn
With the excitement and activity of A-MAZE calming down, I finally have a moment to write about a rich book that I will want to read again and again- Vehicles: Experiments in Synthetic Psychology by Valentino Braitenberg. Since it was written in 1984, I’m truly lucky that a colleague from the Gamelier recommended it to me, or else I doubt I would have ever discovered it.
The principle of “Synthetic Psychology” invoked in the title is that relatively simple machines can exhibit complex behavior that we would classify as “living”, “instinctive” ,” willful”, “smart”, “attentive”, etc. The author does this by setting up a series of thought experiments. He begins with a “vehicle” with a single motor activated by a sensor that is attuned to the temperature of its immediate surroundings.
Things get immediately more interesting in the next example, where a vehicle has a motor and a sensor on both sides. Depending how the connections are made between the motors and sensors (same side or crossed), and whether the connection is positive or negative, the vehicles would circle a source of heat, charge right at it, run away from it.
This is only the beginning. Each chapter introduces new layers of complexity into these simple vehicles and then explores how the vehicles would behave in such and such circumstances. He explores non-linear activation, thresholds, connections networks, selection, resistant connections, and many others. Some of these concepts reminded me of the little I learned about neural networks in school, but the author explains each wrinkle gently enough that I don’t believe any prior knowledge is necessary to enjoy it.
Ultimately, the book nicely sidesteps the question of “intelligence” that pollutes common discussions of artificial intelligence. By the time you are in the middle of the book, you have to admit that the machines behave in a way that you only associate with living things, and yet they are made only of sensors, motors, and wire.
The appendix to the book is filled with biological references for the mechanisms introduced as purely mechanical. Given that the book is now 30 years old, It would be interesting to know what new has been discovered since then.
Oh, and there are lovely line drawings placed in the middle of the book that evoke faraway worlds and fantastic machines. This reminds me of what an incredible video game it would make, especially the complex “social” aspects of having a world of such vehicles!
“What Video Games have to Teach Us about Learning and Literacy” is a book about how video games motivate players to learn how to play them, despite or even due to their complexity and difficulty. James Paul Gee compares how players learn video games to how people learn in school, and discusses how schools and other learning environments would benefit from imitating these aspects of video games.
For me, the most interesting sections of this book dealt with the importance of identity. James Paul Gee argues that learners take on an identity with regards to a field of study. The identity can very well be positive- someone who is good at the subject, who learns quickly, performs well, etc. But they just as easily be negative, in which case the learner will be scared and put off by taking on the subject in the future. The author says that such a learner is “damaged”, and that such damage is difficult and time-consuming to repair.
This rings true of my own experience. I always did fine in school, but definitely formed negative relationships with certain subjects. In particular, despite five years of studying Spanish in junior-high and high school, I never really learned enough to converse. I therefore decided that I was a “language idiot”, and that I was forever handicapped in that area. I suppose that this demission was comforting, since it meant I didn’t have to try. When I ended up in France, it was so frustrating to not be able to understand and relate to those around me that I was extremely motived to learn. And the reality is that I can learn languages just fine. I still wouldn’t say that I’m “talented” in languages, but putting in hard work over a long enough period of time is likely the secret to learn anything at all.
The author show how the notion of identity extends to the people who work in the field. For example, doing science effectively makes the learner a scientist. The closer the learner associates themselves with the values of a scientist, the easier this learning becomes. Once again, the opposite is also true. A person could be easily put off a field by not wishing to associate themselves with the a negative identity they associate with it.
This now makes a few books that I’ve read which make this argument that school teaching techniques should import game design principles. But though I accept that video games mentioned do teach something, and may teach them very well, it is hard to find an example of an existing game that teaches something of value outside the game itself (besides side-benefits such as hand-eye coordination, willingness to experiment, or positive self-esteem). May it be that not enough games are built around real systems? Or is it fundamentally harder to get people to play a game about physics or language than it is to get them to jump on platforms, associate colors, and aim at zombies? Could it be that games mostly motivate people to learn intuitively, and not formally? Is school just not playful enough, or is it just harder to make certain subjects both playful and meaningful at the same time?
Ultimately, both educators and game designers are asking a person to invest their time and effort. If you don’t believe that the benefits are worth the investment, than why put in the time? Many (perhaps most) games offer some kind of immediate benefits of pleasure, both spectacular and of solving problems. Could school subjects offer the same?
Rules of Play: Game Design Fundamentals was written by Katie Salen (who co-created Quest to Learn) and Eric Zimmerman (from the NYU Game Center). Its is a BIG book, by which it means it covers a lot of ground, but also that is very long. I have to that I wish it went about twice as fast it does. But perhaps I’m not the target audience, as I already know a lot of material covered from other places. Also, I’m not as interested in game studies as I am in design and development, and so chapters on “games as culture” don’t exactly float my boat.
My favorite part of the book is the game design challenges/exercises, which include the excellent Exquisite Corpse Game Game, which I’ve gotten a chance to try out at Gamelier and found it a lot of fun. There are also some new games, commissioned just for the book, and include essays by the creators explaining their design path and choices. I can’t wait to playtest them.
There are also quite a few points that made me pause to reflect. Here are my notes:
Page 34: The notion of meaningful play encompasses the principle that players should be presented with choices that have a impact on the future of the game experience, and that players understand this (implying a tight feedback loop).
Page 63: In order to analyze how meaningful the choices presented to the player are, they can analyzed in terms of: what happened just before the player was given the choice, how was the choice conveyed to the player, how did the player make the choice, what was the result of the choice, and how was the result conveyed to the player.
Page 91: The four traits that distinguish video games are “immediate but narrow interactivity”, “manipulation of information”, “automated complex systems”, and “networked communication”.
Page 155: The complexity of games can be analyzed as lying along a spectrums: fixed (meaning no complexity), periodic (a simple cycle), complex (the sweet spot), and chaotic (essentially random). The goal is to make a system that is truly emergent, neither random nor unrelated to the interactions of the system itself.
Page 224: Feedback loops affect games in different ways. Negative feedback stabilizes the game, and positive feedback destabilizes it. Negative feedback prolongs the game, whereas positive feedback ends it. Positive feedback magnifies early successes, and negative feedback magnifies late ones (an interesting insight that I hadn’t grasped before).
Page 268: Players can be categorized in terms of how and why they break the rules. Unsportsmanlike players and cheats violate rules where they can in order to win. Spoil-sports simply don’t care about the rules, nor about winning!
Page 425: Ace of Aces was a two-player dogfighting game created as a picture book! Like a choose-your-own-adventure, except each player sees a hand-drawn picture from the point-of-view of the cockpit, and picks from a large set of maneuvers. Both players announce their moves, then turn corresponding pages in their books to find out what happened. You could even play by yourself!
Page 450: The “immersive fallacy” is the idea that video games are moving towards a completely immersive experience of 3D sound and video and touch and smell, as portrayed in TV and movies (The Matrix, Star Trek, Caprica, etc.). Instead, the authors argue that gamers are always playing on several levels, including meta ones in which they know they are just playing a game, and that’s a lot of fun of it. Also, a lot of media can be “immersive” without overloading the senses- like books!
Page 581: Suspicion was an unpublished game to be played over time in an office. Each player gets cards assigning them to two groups: one sect and one institution. They can team up with either of the two in order to win, but no one knows who is who, and so there’s a lot of double crossing going on. Too bad I can’t find out much about it on the internet.
It’s a pretty long book (370 pages), but very well written. I highly recommend reading at lest the first few chapters. The author explains how playing games is essentially doing “work” for our brains and bodies, and how, quite logically, humans have evolved to enjoy doing work. But the activities that we consider games are tweaked in such a way that this work is enjoyable- having clear goals, difficult but not impossible obstacles, rich feedback on our progress, and “fun failure” (I would also add pleasurable surprises to this list). She then gives examples of how we can turn what normally is considered “work” into a game experience. This is very close to what is considered “gamification”, but not in the shallow sense of the points and badges to which this term often refers.
Near the end of the book (chapter 10), she brings in theories of happiness from the positive psychology movement. She believes that psychologists already know what makes people happy (making a positive impact on the world, valuing others and being valued by them, feeling productive and in control, etc.) but that despite the backlog of self-help books, people have trouble making themselves behave in ways that lead to their happiness. And so she designed games that are expressly made to make people happy in ways that align with positive psychology theories.
The most curious one takes place in a graveyard. Apparently, thinking about death is supposed to make us happy, by making us more appreciative of our health and opportunities, as well as more forgiving of the “small stuff” that annoys us. It seems that graveyards used to be spaces for events outside of funerals, but now most graves are only visited 2 times after the funeral, if ever at all. And so she made a game called Tombstone Hold’em to make players reflect on death and have fun doing it.
The Nightscience Hackathon just finished, and I’m writing this on the long train ride home. It was a lot of fun, and though we didn’t get nearly as far as we had naively hoped, I’m happy that we have a decent proof-of-concept to show about our evolution game.
Please go ahead and play it, but don’t be afraid to come back if you need some explanations. We mostly tested it under Google Chrome, but it should work in other modern browsers as well (perhaps without the sound).
My night train was canceled due to the horrible train accident near Paris, and so I arrived just before lunch. I found that the Hackathon had already split into groups that had rallied around an idea. Not all groups included programmers, and they discussed improving education and research through technology and open data. But one of them wanted to make a game, a game about evolution.
That, unfortunately, was about all the group had agreed on, and so we spent almost the whole day exploring and trying to agree on what game we could make that would be fun, educational, and of course do-able during such a short time. Luckily Marc Planard (@corpsmoderne) was in the group, a talented and excited game programmer working at MekEnSleep. We also had Stéphane Libois, Laurent Arnoult, Cecile Quach, and two others whose names I have lost. But we didn’t have any artists in the group, which made is so that the game is pretty ugly.
We debated many ideas. I was originally pushing having creatures moving along on a map, meeting and breeding with others. Then we focused on an idea of breeding “champions”, like horses or plants, that you use to fight adversaries. Through applying artificial selection to them, you could make strong creatures that are powerful enough to beat your opponents. But we had a hard time at first making this idea work. How could the creatures interact in an interesting and non-obvious way, and yet still allow the player to pursue a goal?
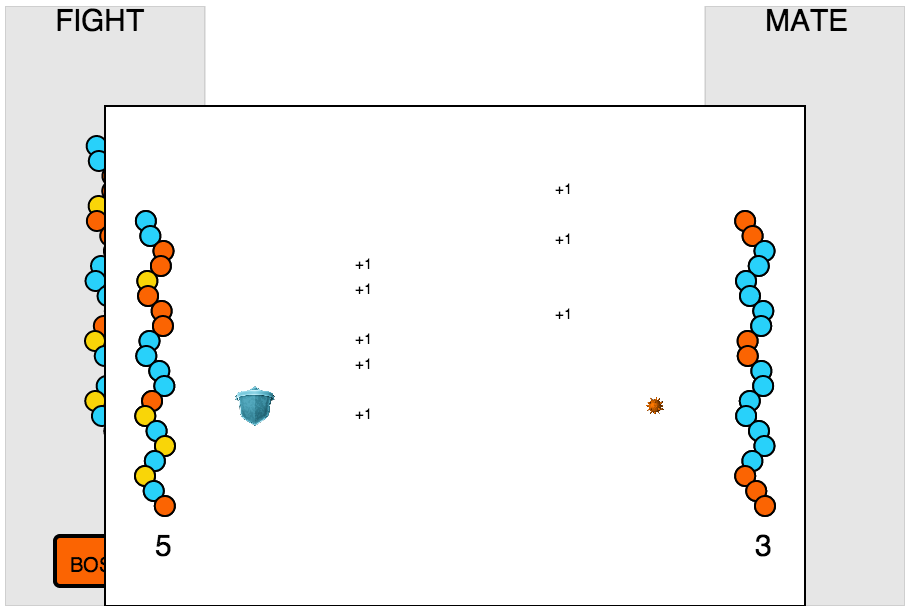
Around 6 in the afternoon, we eventually hit upon the idea of having a single strand of “genes” that determine how each creature behaves. There are 3 types of genes: attack, defense, and reproduction. When two creatures fight, they take turns attacking and defending each other. Each group of attack genes count as a single attack. If there are more genes in that group than in the opposing defense gene group, counting from the top, then the attacker scores a point. And now the other creature can attack.
If a creature loses a fight, he disappears. But luckily you can mate creatures together. When you do this, the two strands are crossed, producing two “children” that are mixes of the parents. There’s also a random mutation factor built-in that keeps the derived sequences from becoming two similar.
When the player has a creature that they think is good enough, he take on the boss. Unlike the randomly created creatures at the games start, the boss was crafted to have a moderate difficulty. In a full game, each level could have its own bosses of increasing difficulty.
We wanted to have something quick to show on the web, so we wrote it all using Javascript. We started with the RaphaelJS graphics library, but ran into problems with dragging and dropping groups (or sets) of shapes, something that it does not support well. So we switched to KineticJS, which neither of us had used before, but which worked pretty well for what we were doing. We also used Buzz for the sound, which was fine, though it took me a while to understand that fading in and out a sound clip did not make it play or stop as I had imagined! Future ideas
Of course, there’s a million things that we could do better with this game concept. First of all is the graphics, which need some serious help. Also, we originally wanted this to be a multiplayer game, so that players could confront the creatures they breed.
There’s also the reproduction gene, which is currently just “dead code” in the genome. But the original intention is to have the number of reproduction genes be proportional to the number of offspring that a creature can have. This would force the player to keep enough reproduction genes to avoid having the lineage come to a sad end.
Another interesting tradeoff would be have a lifetime associated with each creature, determined either by a number of “health genes” or inversely proportional to the length of the genome, if it was allowed to vary.
Where’s the code?
Under the extreme time pressure, I’m not putting this code out as an example of good coding practices… it’s pretty ugly! But if you’re interested, please grab the code on Github and hack away.
Overall, its focus is squarely on modeling game economies, rather than other types of mechanics, which do not apply as easily to the kinds of games that interest me. However there are a few tasteful tidbits in there that are well worth mentioning:
The categorizations of game mechanics (physics, internal economy, progression, tactical, social) are a useful way to make sure to consider other possible mechanics to introduce into the game. The discussion of emergence vs. progression in games, and how the two can be mixed, is also an interesting perspective.
The heart of the book presents a way of modeling game economies with a model called Machinations, which you can find online. For small examples, the approach provides a way to visualize and to simulate feedback mechanisms in game economies. Economies are a natural way to understand some types of games, like Monopoly and war strategy, but other games need to be twisted a bit to fit into this framework. Nevertheless, recognizingpositive and negative feedback loops is a key tool for any time of game design, and one that the book explains in good detail. The book also provides a few “design patterns” based on this framework, which are recognizable from examples.
The book has an extensive discussion on different types of key-and-lock mechanisms, and describes how one of the most important jobs of the level designer is cleverly disguising keys and locks as other things, such as new weapons, new spaces, etc.
The last chapter was a real treat, as it discusses how simulations differ from games, and how serious games differ from entertainment games. They also discuss how game mechanics can be given meaning, and how conflicting layers of meaning can provide depth to otherwise trivial games. The discussion is rooted in semiotics, which I didn’t know about before and was happy to learn.
I just got back from a 3 day trip at the beautiful and mysterious PAF, in the countryside near Reims, about 2 hours east of Paris. The place is made for artists, dancers, and musicians to work, think, and play. And at only 16€ a night, an incredible deal. An ancient monastery, it’s still filled with objects of previous grandeur like out-of-tune pianos and stringy tapestries, but who can say no to a kick-ass ping-pong table?
But as their website says, it’s a place for “production” not for “vacation”. And that’s what the 9 of us were there to do. Import Wikipedia into KnowNodes, visualize it on a graph, and let users quickly find these articles when making connections.
Know your Nodes
So what is this KnowNodes project, you may be asking. Dor Garbash‘s dreamchild, it is a connectivist orgasm, a sort of map of human thought and knowledge, but focused the connections between resources (scientific articles, blog posts, videos, etc.) rather than on those resources themselves. Students could use it to find new learning resources, researchers could use it to explore the boundaries of knowledge in their field, and the rest of us just might love jumping from one crazy idea to the next.
Much like a new social network, one recurring problem with getting this kind of project of the ground is it needs good quality content to jumpstart it. And what could a be better source of quality information as the world’s largest crowdsourcing project ever, Wikipedia?
Now down to the gory details. How big is Wikipedia, anyway? Well, according to the “Statistics” page, the English-language site is at 30 million articles and growing. Wikipedia (and the Wikimedia platform behind it) is very open with their data. You can easily download nightly data dumps of their database in different formats. But here’s the rub: the articles alone (not counting user pages, talk pages, attachments, previous versions, and who knows what else) still weighs in at 42 GB of XML. That was a bit too much for our poor little free-plan Heroku instance to handle.
So, we came up with a better idea: why not just focus on a particular domain, such as computer science? That way we could demonstrate the value of the approach without overloading own tiny DB. Now, we realized that we couldn’t just start at the computer-science article and branch outwards, because with the 6-degrees nature of the world, we would soon end up importing the Kevin Bacon article. But Wikipedia has thoughtfully created a system of categories and sub-categories and sub-sub-categories, and anyway, how many articles under the Computer Science category category could there possibly be?
1+6+2+5+9+17+3+34+…
Hmmm, let’s find out. We wrote a node.js script that uses the open Wikimedia API. The only way to find all the articles in the Computer Science category hierarchy is to recursively ask the API for the categories within it, do the same with its children, and so on, until we reach the bottom.
The nodemw module came in really handy, as it wraps many of the most common API operations so you don’t have to make the HTTP requests yourself. It also queues all requests that you make, and only executes one at a time. That prevents Wikipedia from banning your IP (which is good) but also slows you way down (not so good).
Enough talk, here’s what we came up with:
And so we launched the script, saw that it was listing the articles, and walked away happily, bragging about how quickly we had coded our part as we watched the peacocks scaring each other in the courtyard.
And when we came back a few hours later, and the article count had surpassed 250000, Weipeng suspected there may be a problem. He started printing out the categories as we imported them, and sure enough we saw duplicates. That was the first sign that something was wrong. The second was when we saw that we had somehow imported an article on “Gender Identity”. That doesn’t sound a lot like computer science, does it?
On further inspection, we found that our conception of how the category system worked was very wrong. It turns out that categories can have several parents, that pages can be in multiple categories, and that categories might even loop around on themselves. This is very different than the simple tree that we had been imagining.
Time for a new approach: we simply limit the depth of our exploration. Stopping at 5 levels was about 110k articles, and 6 levels gave us 192k. We couldn’t find any automatic criteria to say whether all these articles really should be part of the system, but this was about the number that we were hoping for, so we stopped there.
Wikipedia -> KnowNodes
Now that we had a list of articles, time to actually put them into the database. Time-wise, it probably would have mad sense to go through the XML dump in order to avoid making live API requests. But then this wouldn’t help us if the users were looking at a new article outside of those we were searching for. And so we created a dynamic system.
The code in this case might not make a lot of sense to anyone who hasn’t worked on the project, but the idea simple enough. Convert the title to the url of the article, download the 1st paragraph (as a description), and insert it into our database. The 2nd part turned out to be much harder than we had thought. Wikipedia uses their own “Wikitext” format, which you wouldn’t want to show by itself. There actually are quite a few libraries to convert from Wikitext to plain text (or to HTML), but very few of the Javascript ones worked reliably in our case. The best we found was txtwiki.js, which really is quite good, except even it fails on infoboxes (which unfortunately are often placed first on the page, messing up our “take the 1st paragraph” approach). In the end, Weipeng found that we could simply ask for the “parsed” or HTML version of the page, and take the text between the first “<p>” tag we found.
Importing a bunch of isolated Wikipedia articles does not create a map of knowledge, making connections between them does. The Wikipedia API provides at least 3 different kinds of links: internal (to other pages on the site), external (to the general internet, as well as to partner sites like WikiBooks), and backlinks (other Wikipedia articles that point to it). We query all 3, find which ones already exist in the database, and setup a link between them.
Code-wise, there’s not much to show that isn’t tied intimately into KnowNodes. Nodemw is missing a method to get internal links, though, so here it is what we wrote:
One foot in front of the other
The last step in this journey was going through the article lists we had generated and making the calls to our own API to load the Wikipedia article. This seems straightforward enough, except that it is bizarrely difficult to read a text file line by line in node.js. Search StackOverflow and you’ll find a bunch of different approaches, including using the lazy model, which works pretty well. But since I knew that our system could only make one Wikipedia request at at time, and that each Wikipedia article involves at least 4 requests (for the article and the 3 types of links) there’s no point overloading the server. I just wanted to read one line at at time.
Line Readerto the rescue. A very minimalist API, but which allows you to asynchronously declare when a new line should be read, and therefore perfect for my needs.
Bonus: Drunken graph walking
Well Weipeng and I were puzzling over inexplicable errors, Bruno was pondering a bigger question: Now that we have all these links, how to know which are more important than others? Among the many planned features for Knownodes is a voting system for the links, but couldn’t we get a good idea from the link structure that already exists on Wikipedia?
Bruno came up with a “friends of friends” approach: Given an article A and an article B that it links to, count the number of articles that that A links to that also link to B. What’s nice about this approach is that it imitates a random-walk along the graph. Imagine you are on the Wikipedia article of A, what is the chance that by following the links you will end up at B in 2 clicks?
In practice, these numbers tend to be very asymmetrical. A subject like “Python” may have a lot of links towards “Computer Science”, but only a small fraction of “Computer Science” links lead to “Python”.
We considered coding this in to the Wikipedia importer, but there’s no reason that the approach shouldn’t work for any type of node and link in the system. And why not learn about querying a graph database in the process?
This was Bruno and I’s first time writing Cypher queries, so I doubt this is the best way to do it, but this is what we came up with:
Although Cypher lacks some documentation (mostly in the form of examples), it actually makes a lot of sense once you start working with it. The graphic representation of the links is a big plus, and the rest of it is reminiscent of SQL for those of us who have used “normal” DBs before.
And there you go. 3 days of good work and good times. Next step? Let’s get a good search box on the KnowNodes front page!
Pretty exciting for me. This has been a lot of work for Quentin and I over the past year, if can believe it. Not that it’s really a year’s worth of work, but just that we had a lot of false starts (originally it was a game set in ancient greece about a character who could move objects with his mind).
There’s a lot that we didn’t do in the end, and a lot of things that I would like to take on in the future, if it get’s a good response.
Although it took quite a bit more effort, I’m glad to say that JC and I managed to update Dog Eat Duck with two major enhancements – animations and sound.
Both make a big difference, and made me realize once again how easy it is to overlook incredibly important stuff. Which is not to say that we hadn’t though that it would great to have the ducks move. But without them moving, a bunch of people though that they were just looking at screenshots!
The sound is also a big help. Although it took me longer than it should have, I finally did manage to get SoundManager2 up and running with a few small MP3s, and the result just makes me smile.